从同义词替换到语义重构,嘎嘎降AI为什么做了不同的选择
如果你用过2023年的降AI工具,大概有这样的体验:把论文丢进去,AI率从90%降到67%,然后就降不下去了。这些工具的逻辑基本一样:换同义词,改句子长短,删掉「首先其次」。
嘎嘎降AI(www.aigcleaner.com)从一开始就没走这条路。
市场上大多数工具在做什么
早期降AI工具的技术思路很直接:找AI惯用的词,换掉它;识别AI惯用的句式,改掉它。这叫「同义替换路线」。
这条路线有个根本性的问题:检测系统判断AI文本,看的是统计特征,不是具体的词。
把「研究」换成「探讨」,困惑度没变;把「首先其次」删掉,句长标准差没变;换了几百个词,语言的统计分布还是AI的分布。检测系统扫一眼,换汤不换药。
实测数据很说明问题:同义替换工具,把AI率从90%降到50%-60%是正常水平,很难再往下了。
嘎嘎降AI选择的路线
嘎嘎降AI的双引擎技术,处理的是两个层面上的AI特征。
语义同位素分析引擎:不是找哪个词可以替换,而是分析整段话的语义组织结构,识别AI特有的语义模式,然后用学术文本中真正常见的表达方式重组。这改变的是语义层面的统计特征——困惑度、词汇多样性、语义连贯性的方式。
风格迁移网络引擎:把AI文本的句长标准差从1.2提升到4.7,改变被动语态比例,引入适度的「人类写作不完美性」。这改变的是结构层面的统计特征。
两个引擎同时工作,五个维度同步处理。检测系统在多个维度交叉验证——嘎嘎降AI在每个维度都做了改变,找不到足够的AI「锚点」。
这个选择意味着什么
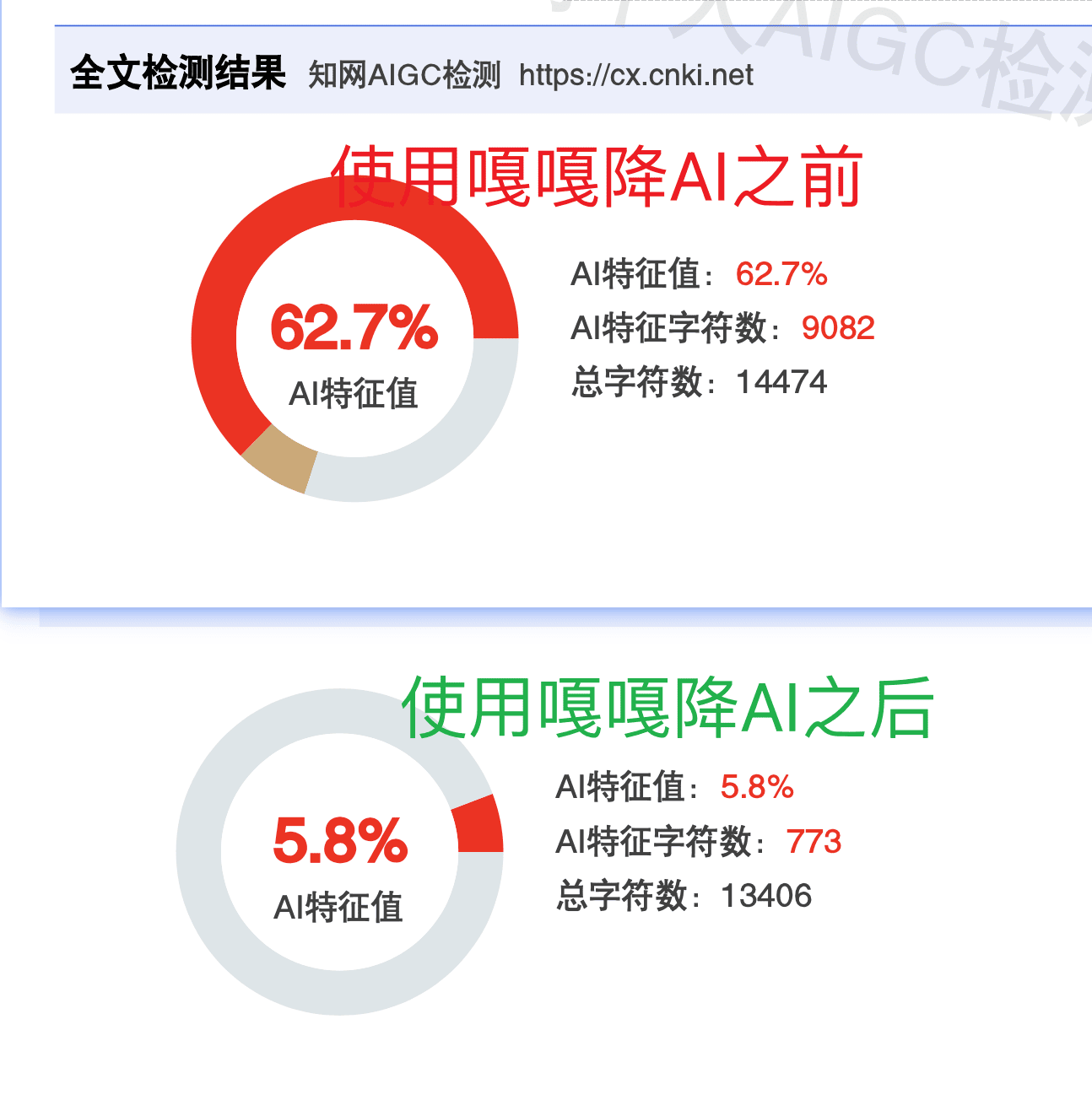
从结果来看,差距非常明显。同义替换工具最好成绩是把90%降到50%;嘎嘎降AI实测72%→6%,前后测5次都在10%以下,达标率99.26%。
从工程难度来看,语义重构比同义替换难得多。同义替换本质上是个词典查找和句式模板匹配问题;语义重构需要真正理解文本的语义结构,然后用不同的方式重新组织,保持意思不变但统计特征改变——这是大语言模型层面的工程。
从对抗算法升级的能力来看,语义重构路线更有持续性。2025年12月知网升级算法,重点加强了语义连贯性检测——同义替换工具几乎全部失效;嘎嘎降AI的处理层面正好跟新算法的检测重点对应,实测依然有效(知网62.7%→5.8%)。
这是技术路线选择在时间上的回报:走对的路,面对算法升级不需要大改方案。
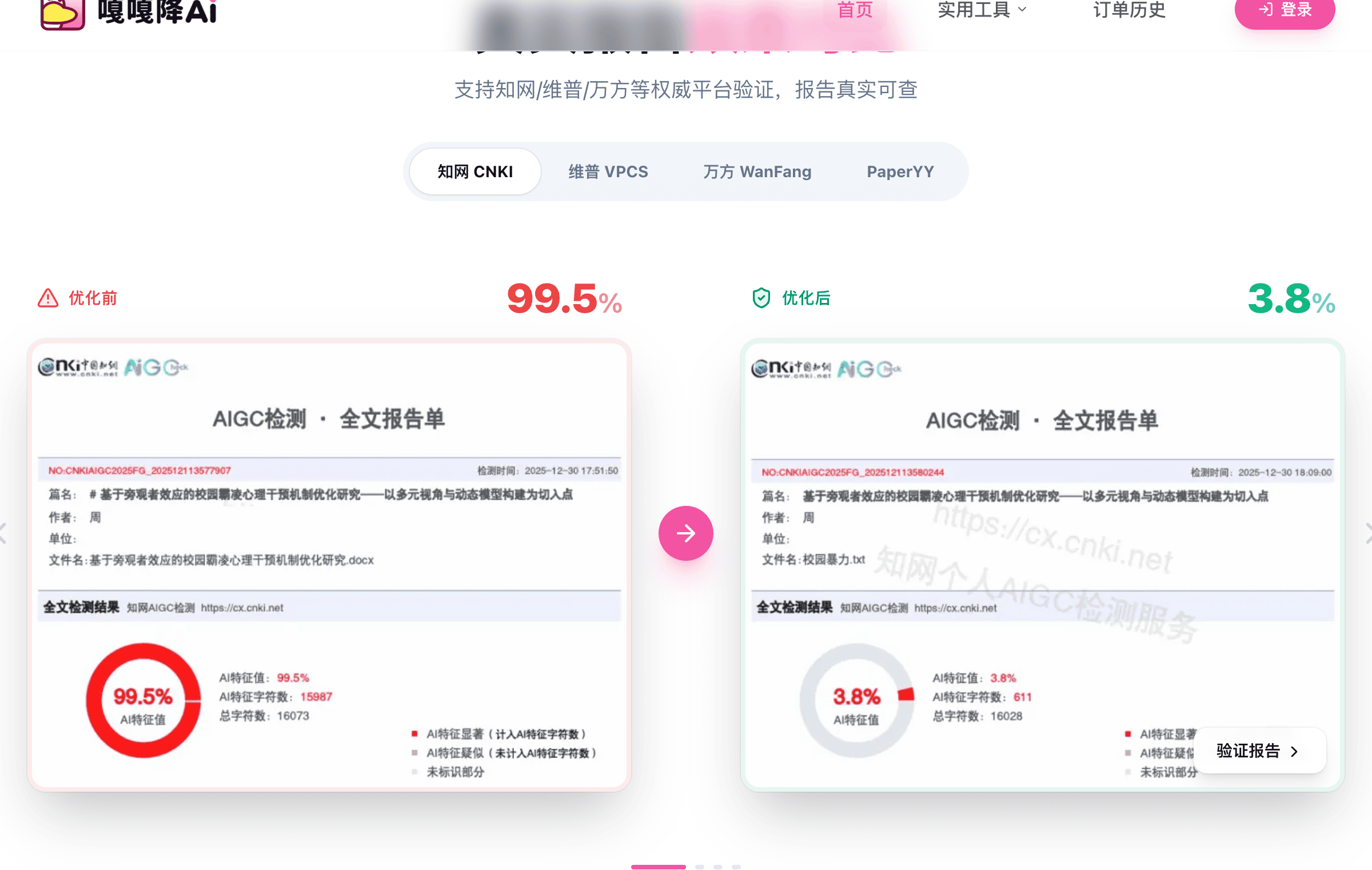
9大平台验证是怎么做到的
知网、维普、万方、Turnitin,每个平台的检测算法不一样,同一篇文章在不同平台的AI率会有差异。
嘎嘎降AI的多平台适配,不是靠「在多个平台上测试过」这种经验性适配,而是因为双引擎处理的是底层的统计特征,而不是某个平台的算法特征。各个平台的检测逻辑虽然不同,但都在检测文本的统计特征——困惑度、句长分布、词汇多样性这些指标是通用的。
这也是为什么可以支持9大平台,而不是「针对知网优化」的专用工具。
价格和保障设计
4.8元/千字,1万字论文约50块。
设计了两层保障:不达标(AI率未降至20%以下)可退款;7天内无限修改,一次付费可以反复处理。
退款保障不只是营销承诺,它意味着工具团队对自己的技术效果有足够的信心,才敢做这个承诺。
降AI工具选择参考
| 工具 | 技术路线 | 价格 | 目标AI率 | 适合 | 链接 |
|---|---|---|---|---|---|
| 嘎嘎降AI | 双引擎(语义+结构) | 4.8元/千字 | <20%,实测个位数 | 本科/硕士,多平台 | www.aigcleaner.com |
| 比话降AI | Pallas自研引擎 | 8元/千字 | 知网<15% | 研究生/期刊,知网专用 | www.bihuapass.com |
| 率零 | DeepHelix重构 | 询价 | 知网个位数 | 严格要求,最深度 | www.0ailv.com |
| PaperRR | 学术级改写 | 6元/千字 | <15% | SCI,术语保护 | www.paperrr.com |
这个市场还在快速变化:检测系统在升级,工具的技术路线在分化。选择技术路线对的工具,比选「现在评分最高」的工具更重要。从统计特征层面处理文本,是应对算法持续升级的正确方向。